Q How to delete duplicate records from a table ?
This is one of the famous question asked by an interviewer. Lets us see how to to delete duplicate records from a table. Table StudentInfo has duplicate records as shown below.
Step 1: First we will create a temporary table say temp and copy all original table (StudentInfo Table) data into this very temporary table.
SELECT * INTO #Temp FROM StudentInfo
Now check data in temporary table # Temp
SELECT * FROM #Temp
We see that all data from original table is copied into temporary table .
Step 2: Now we will delete all the duplicates record from the temporary table. For this, we will first group all records by ID and take the count of each group. Then we will delete those ID whose count is greater than 1.
DELETE FROM #Temp
WHERE ID IN (SELECT ID FROM StudentInfo GROUP BY ID HAVING COUNT(ID) > 1)
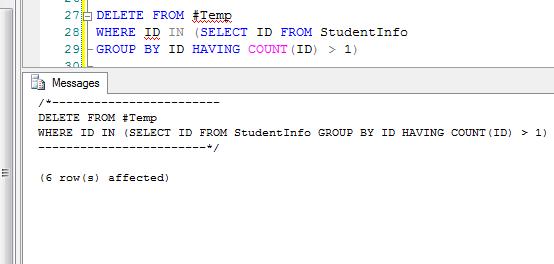
All 6 duplicates records are deleted from temporary table. 2 non duplicate record is left in the temp table.
SELECT * FROM #Temp

Step 3: Now we will insert distinct records of duplicate records into temp table from original table as shown below. In this way , now temp table holds all distinct records.
INSERT INTO #Temp SELECT DISTINCT Name,ID
FROM StudentInfo GROUP BY Name,ID
HAVING COUNT(ID) >1

Step 4: Empty the Original table(StudentInfo).
DELETE FROM StudentInfo

Step 5: Now we will insert all the distinct records present in the temp table to the original table StudentInfo.
INSERT INTO StudentInfo SELECT * FROM #Temp

Step 6: Since there is no use of temp , we can drop that table.
DROP TABLE #Temp
Step 7: Now , the original table contains only the distinct records. All duplicates has been removed. we can see this as mentioned below.
SELECT * FROM StudentInfo

There is other popular way to delete duplicate records from the table using ROWID :
DELETE FROM <TableName> WHERE ROWID NOT IN
( SELECT MIN(ROWID) FROM <TableName> GROUP BY <ColumnName1> <ColumnName2>...)
This is one of the famous question asked by an interviewer. Lets us see how to to delete duplicate records from a table. Table StudentInfo has duplicate records as shown below.
 |
| SudentInfo Table |
SELECT * INTO #Temp FROM StudentInfo
Now check data in temporary table # Temp
SELECT * FROM #Temp
 |
| Temporary Table |
We see that all data from original table is copied into temporary table .
Step 2: Now we will delete all the duplicates record from the temporary table. For this, we will first group all records by ID and take the count of each group. Then we will delete those ID whose count is greater than 1.
DELETE FROM #Temp
WHERE ID IN (SELECT ID FROM StudentInfo GROUP BY ID HAVING COUNT(ID) > 1)
All 6 duplicates records are deleted from temporary table. 2 non duplicate record is left in the temp table.
SELECT * FROM #Temp
Step 3: Now we will insert distinct records of duplicate records into temp table from original table as shown below. In this way , now temp table holds all distinct records.
INSERT INTO #Temp SELECT DISTINCT Name,ID
FROM StudentInfo GROUP BY Name,ID
HAVING COUNT(ID) >1
Step 4: Empty the Original table(StudentInfo).
DELETE FROM StudentInfo
Step 5: Now we will insert all the distinct records present in the temp table to the original table StudentInfo.
INSERT INTO StudentInfo SELECT * FROM #Temp
Step 6: Since there is no use of temp , we can drop that table.
DROP TABLE #Temp
Step 7: Now , the original table contains only the distinct records. All duplicates has been removed. we can see this as mentioned below.
SELECT * FROM StudentInfo
There is other popular way to delete duplicate records from the table using ROWID :
DELETE FROM <TableName> WHERE ROWID NOT IN
( SELECT MIN(ROWID) FROM <TableName> GROUP BY <ColumnName1> <ColumnName2>...)
nice one :)
ReplyDeleteThanks Prakash.
DeleteGud one... :)
ReplyDeleteThanks Anurag.
DeleteAwesome piece of work :)
ReplyDeleteThank u Saurabh :)
ReplyDeletewhy can't we do it using dense_rank and partition
ReplyDelete